노타(대표 채명수)는 퓨리오사AI의 데이터센터용 NPU에서 LG AI연구원의 국가대표 AI 모델 K-엑사원(EXAONE) 236B 최적화에 성공했다고 밝혔다.
K-엑사원 236B는 약 2,360억 개 파라미터 규모의 대형 AI 모델로, 여러 전문가 모델을 선택적으로 활용하는 MoE 구조를 채택하고 있다. MoE 구조는 대형 모델의 효율을 높일 수 있지만, 최적화 과정에서는 각 전문가 모델이 안정적으로 작동하도록 하는 정교한 기술이 필요하다. 특히 프론티어급 대형 모델은 복잡한 문제를 풀 때 긴 추론 과정을 거치기 때문에, 양자화 과정에서 생긴 작은 오차도 누적되면 최종 답변의 정확도에 영향을 줄 수 있다. 이번 성과는 이러한 대형 모델을 국산 NPU 환경에 맞게 최적화하면서도 주요 평가에서 정확도를 유지했다는 점에서 의미가 있다.
노타는 이번 프로젝트에서 K-엑사원을 퓨리오사AI의 데이터센터용 NPU 환경에 맞게 최적화했다. 모델 전체를 다시 조정하는 방식이 아니라, 성능 저하가 발생할 수 있는 일부 구간을 정밀하게 분석하고 필요한 부분에만 최적화를 적용해 성능 손실을 최소화했다. 이를 통해 대형 AI 모델을 국산 NPU 환경에서 효율적으로 구동하면서도 주요 성능 지표에서 기준 모델 수준의 성능을 유지했다.
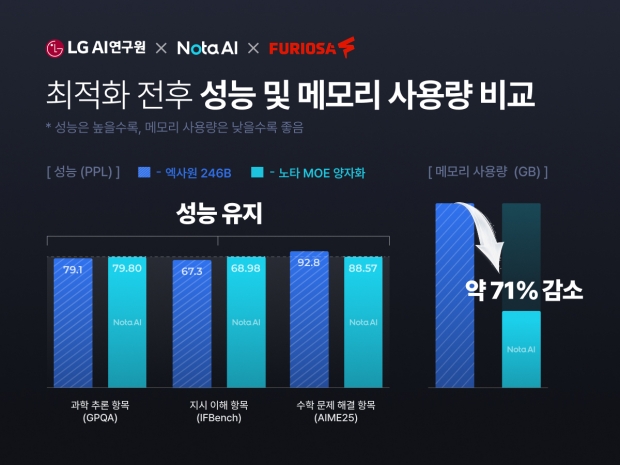
성능 평가에서도 의미 있는 결과가 확인됐다. 노타는 K-엑사원의 모델 크기를 약 71% 줄여 대형 AI 모델 구동에 필요한 메모리 부담을 낮추면서도, 과학 추론, 지시 이해, 수학 문제 해결 등 주요 평가 항목에서 원본 모델과 유사한 수준의 정확도를 유지했다. 이는 같은 2,360억 개 파라미터 규모의 모델을 더 효율적으로 실행할 수 있도록 최적화했다는 의미로, 데이터센터 AI 인프라의 운영 효율을 높일 수 있는 가능성을 보여준다.
자체 평가 환경 기준으로 노타가 최적화한 모델은 과학 추론 항목(GPQA) 79.80점, 지시 이해 항목(IFBench) 68.98점, 수학 문제 해결 항목(AIME25) 88.57점을 기록했다. 모델 크기를 줄이기 전 원본 모델의 성능은 각각 79.1점, 67.3점, 92.8점으로, 최적화 이후에도 3개 주요 평가 항목 단순 평균 기준 원본 대비 약 99.2%의 정확도를 유지했다.
이번 성과는 대형 AI 모델을 국산 NPU에서 단순히 실행한 것을 넘어, 실제 서비스에 필요한 성능과 안정성을 유지할 수 있음을 확인했다는 점에서 의미가 있다. 특히 퓨리오사AI의 데이터센터용 NPU, LG AI연구원의 고도화된 AI 기술력, 노타의 AI 모델 최적화 기술이 결합해 국내 AI 생태계 안에서 고성능 LLM 운영 가능성을 보여준 사례로 평가된다.
최근 글로벌 AI 산업에서는 최첨단 AI 모델과 이를 구동하는 인프라에 대한 접근성이 중요한 이슈로 부상하고 있다. 특히 일부 AI 모델과 인프라를 둘러싼 수출 통제 논의 이후, 각국이 자국 내 AI 모델과 컴퓨팅 인프라를 확보하려는 소버린 AI 흐름도 주목받고 있다. 이러한 상황에서 이번 성과는 국산 AI 반도체와 국내 AI 모델, 그리고 이를 연결하는 최적화 기술이 함께 발전해야 한다는 점을 보여준다.
노타 채명수 대표는 “소버린 AI가 주목받는 흐름 속에서 중요한 것은 모델, 반도체, 최적화 소프트웨어가 하나의 실행 가능한 AI 인프라로 연결되는 것”이라며 “이번 성과는 퓨리오사AI의 데이터센터용 NPU, LG의 국가대표 AI 모델 K-엑사원, 노타의 최적화 기술이 결합해 대형 AI 모델의 실제 운영 가능성을 확인한 사례”라고 말했다.

뉴스타운
뉴스타운TV 구독 및 시청료 후원하기
뉴스타운TV












![[속보] 홍명보 감독, 월드컵 조별리그 충격적 탈락 대표팀 사령탑 자진 사퇴](/news/thumbnail/202606/707471_661507_3540_v150.jpg)








![[단독] 북한산 인수봉, 구조 헬기 긴급 출동 장면 포착!](/news/photo/202511/669971_628773_447.jpg)






